Face Recognition
last update: 19 Nov. 2019

Do you recognise this person? Would you buy a used car from him? Well, it's a blended image of Trump and Putin. It looks quite convincing, and it might well have fooled a face recognition program in 2010, but would it fool it today?
This webpage is dedicated to looking at face recognition from the viewpoint of a technology that is increasingly being used to verify or identify people.
Face recognition is a hot topic. The idea is that face recognition can be used to identify repeat customers, shoplifters, missing persons, and even potential terrorists. Face recognition cameras are seen as a cornerstone of the surveillance capability of the archetypal ‘smart city’, and experts are telling us they will result in 30% to 40% fewer crimes.

Private businesses, such as in the retail sector, want face recognition for security and business intelligence purposes. Law enforcement and border security agencies also want this technology, and it appears to be finding a strong footholds in places where there are fewer privacy barriers.
In the US face recognition is being used, but often people who are arrested with the help of face recognition aren't aware that it was used against them. Face recognition is often not used as evidence and thus never appears in court. As such face recognition has not been the subject of many judicial rulings.
![]()
What put face recognition high on my 'radar screen' was an article in September 2019 that mentioned that the Chinese had ruled that a face scan must be made (along with a follow-up ID check) for anyone applying for mobile and Internet services. In October 2019 the US decided to blacklist Chinese face recognition companies citing human right violations against Uighurs, Kazakhs, and other Muslim communities in Xinjiang (probably just another move in the ongoing US-China trade war). Over the last 2-3 years stories coming out of China have been increasingly focused on the use of face recognition in all parts of daily life.

Chinese police are being equipped with smart sunglasses that pick up facial features and car registration plates, and match them in real-time to a database of suspects. One estimate suggested that there were already 200 million surveillance cameras installed in China in 2018, and the figure could rise to more than 600 million by 2020.
National biometric ID programs in China and India, started in 2013 and 2011 respectively, are seen as major drivers for biometric technologies over the next 5-10 years. In fact India has launched the Aadhaar program which is the largest biometric-backed national identity scheme in the world (more than 1 billion people will receive ID numbers supported by fingerprint and iris data). You can checkout biometric applications in places as far afield as Kenya, Nigeria and Brazil on Biometric Update.
This is a video (sorry about the ads) called "Chinese Street Surveillance" dating from Sept. 2017, and this BBC video is called "China: the world's biggest camera surveillance network", and dates from Dec. 2017.
It is clear that the face recognition market is growing, that many Chinese companies are active in the field, and that the application of surveillance technology, including face recognition, could rapidly become pervasive in all major Chinese cities. On top of all that the Chinese government is constantly touting its high-tech surveillance successes. Criminals are being caught and jaywalkers are being shamed in public. But the reality is that the systems still have severe limitations, i.e. whist being very accurate they cannot (today) scan and identify simultaneously and in real-time 1,000's of people in different places in a city. Today system such as Face++ are best used on local servers equipped with a local gallery designed for search in specific locations such as a train station. Systems able to handle simultaneously 1,000's of faces don't (yet) exist. Also it was noted that jaywalkers are being identified, but there is a delay of 5-6 days between when the event occurred and when it is finally posted in the public domain. And it was reported that it was the police that reviewed the video to find and shame the jaywalkers. Another report concerning the use of smart sunglasses mentioned that they only work if the subject stands still for several seconds, so they are not that useful for spotting criminals, but are used to verify travellers' ID's.
Of course the key is that people don't actually know if they are being monitored or not, and that makes them more docile and law-abiding. Also what is not possible today, might well rapidly become commonplace tomorrow.
We should not forget that the US Homeland Security's Office of Biometric Identity Management operates the second largest biometric system in the world, after the Indian Aadhaar system. The Automated Biometric Identification System (IDENT) is home to 230 million unique identity records, and can also access databases from the FBI and DoD (the databases are growing by 20 million identities annually). Today it processes 350,000 transactions daily, and returns a 'yes' or 'no' 99.5% of the time. A new system, the Homeland Advanced Recognition Technology (HART), will soon replace IDENT and is expected to be able to handle 720,000 requests daily (it is planned to be scalable to 3 million requests daily). HART will include face biometrics as well as iris, voice and DNA biometrics. Naturally not to be outdone by Homeland Security the FBI has its own plan for a Next Generation Identification (NGI) System which will include an interstate photo and face recognition system with 30 million mugshots.
As of October 2019 the bipartisan Commercial Facial Recognition Privacy Act (S-847) is going through the US Congress. The bill will oblige companies to first obtain explicit user consent before collecting, sharing or selling any face recognition data (but it does not apply to federal or state authorities). In addition there are two pieces of legislation (HB 1654 and SB 5528) in Washington State that aim to prohibit the use of face recognition systems by state, local and municipal agencies (it would be illegal to acquire, possess, access or use any biometric surveillance system). San Francisco has already prohibited the use of face recognition technology (see example below).

This is a video by Wired from Aug. 2019 called "Why Some Cities are Banning Facial Recognition Technology".
New References (to be integrated into the text at a later date)
2020.05.31 Andy Greenberg "Now to Protest Safely in the Age of Surveillance"
2020.05.29 Caroline Haskins and Ryan Mac, "Here Are The Minneapolis Police's Tools To Identify Protesters"
What is Face Recognition?
Wikipedia has a decent introduction to the 'facial recognition system', and we learn that it is a technology used to identify or authenticate a person from an image or video source. The basic idea is to compare facial features from an image or video source with faces held in a database. These features include facial texture, shape, and relationships (e.g. distances) between different 'landmarks' on a face such as eyes, mouth, etc.

The most obvious application is in computer security with the use of biometrics (including fingerprints, iris recognition, voice analysis, finger vein recognition, signature recognition, etc.) for access control.
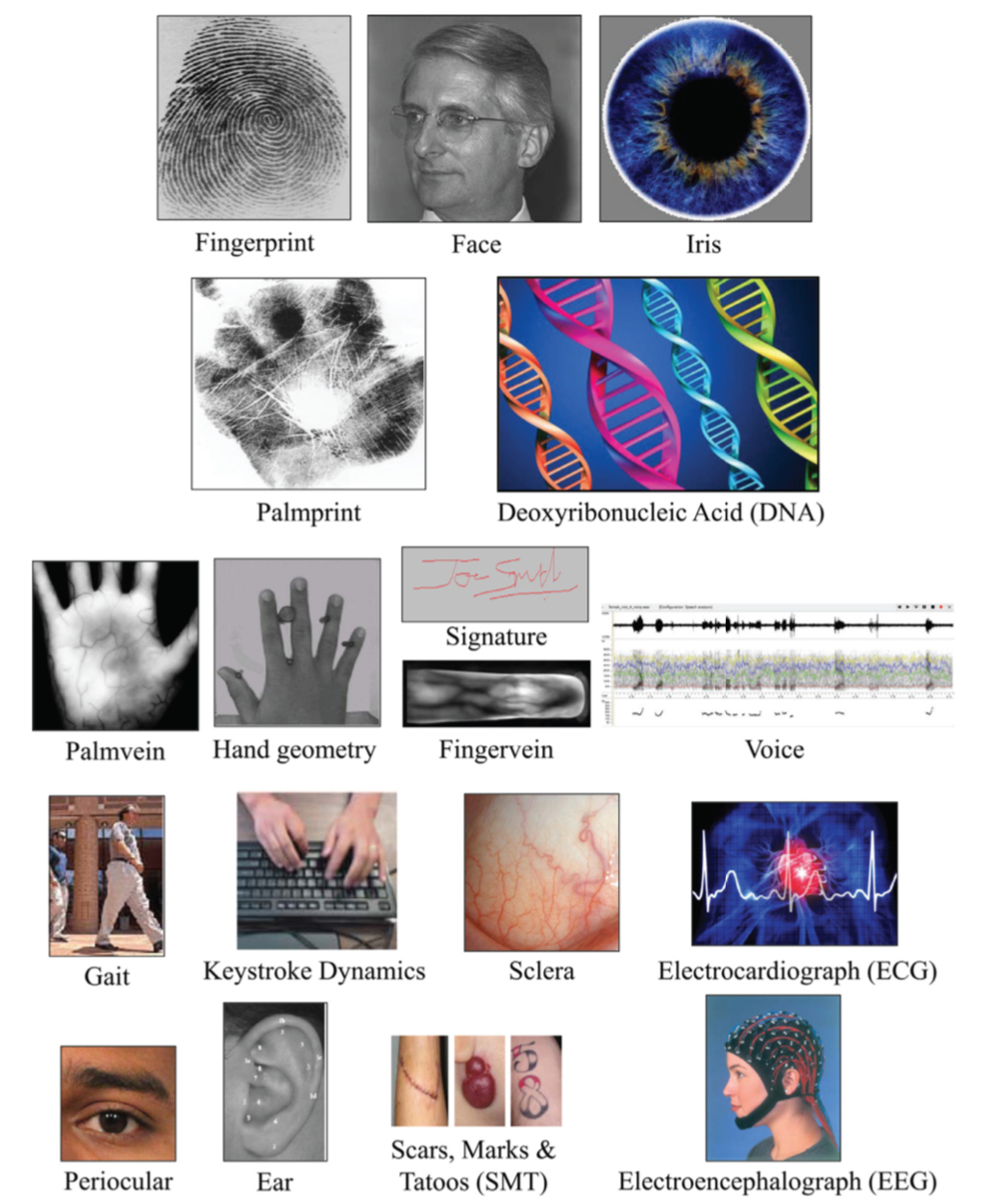
The above diagram was taken from a 2015 research paper entitled "50 Years of Biometric Research: Accomplishments, Challenges, and Opportunities".
Biometrics is usually divided into two distinct groups, physical characteristics (e.g. iris, face, fingerprint, DNA, etc.) and behavioural characteristics (e.g. signature, voice, keystroke, etc.). Another, less obvious, distinction between different biometric technologies is between contact and contactless, e.g. face recognition being a contactless technology. Although it must be noted that contactless payment cards are becoming increasingly popular and 'contactless fingerprinting' is also being tested (i.e. where the owners payment card has a built-in fingerprint scanner, so they don't need to touch the reader).
An important trend has been the way credit card security has gradually evolved. Initially the credit card had a magnetic strip and required the user to sign for a payment. Then came the chip card with a PIN, and now we have the chip or smart card with a PIN and contactless operation. This allowed a faster transaction and enabled the introduction of a low transaction limit that does not require a PIN entry. What is being trialed now is a biometric duel-interface card. This is the same chip card but it now includes a biometric (fingerprint) chip. So the user 'validates' the payment with a fingerprint scan on the chip card itself (which remains contactless). What might be on the horizon is to integrate into these new biometric cards a dynamic CVV/CVC code, providing a one-time password display function.
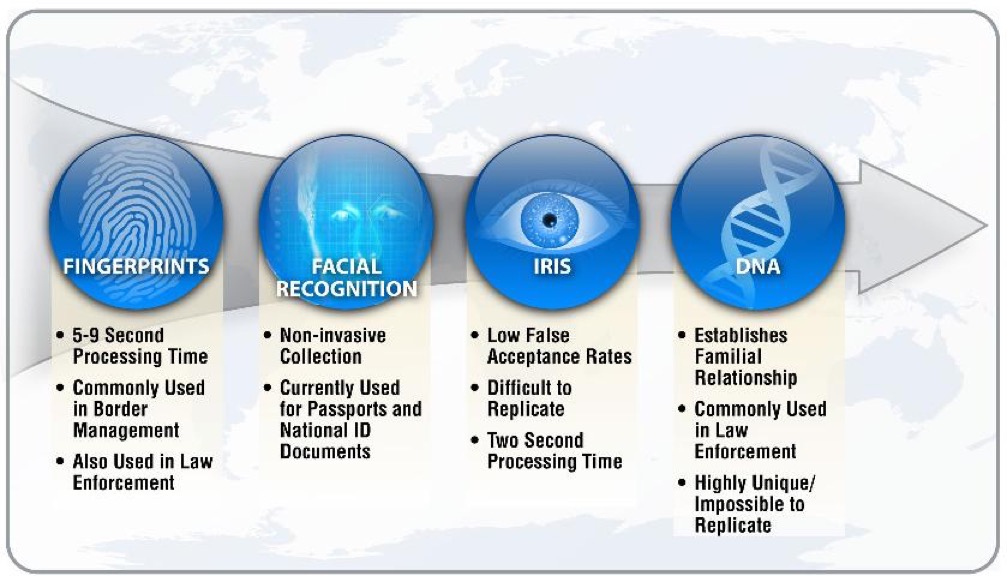
As shown above each biometric technology has its strengths and weaknesses. Here is a video from Mar. 2019 that's entitled "Facial Recognition: What you need to know about tech that knows you".
The market for biometric technologies, which is different from the market for biometric systems and solutions, is estimated to be growing at nearly 20% annually, and will reach nearly $11 billion by 2022. Biometric technologies are the bits that we increasingly see integrated into ATM's and our smartphones, etc. For example, fingerprint technologies have become widely accepted because they are both relatively reliable and affordable. The market for all forms of biometric systems is expanding at about 35% annually, and is expected to reach nearly $70 billion by 2024.
The use of face recognition technologies is also expected to grow substantially in particular for smartphone applications. It has been estimated that by 2024 the global face recognition market will be about $7 billion, and will grow at about 16% annually. The key sector for growth in the near future is the public sector (security, law enforcement, health), but the retail sector is also looking for ways to identify loyal customers and thieves, and face recognition looks to be ideally suited to this task. Not everything is linked to face recognition, for example iris recognition is increasingly being used for access control to government buildings, airports, and points-of-entry on borders, etc. And it is quite possible that we will see iris recognition on smartphones by 2024.
Security applications include ID validation, fast track boarder checks, police ID checks, and face recognition in mass events using drones. Face recognition is expected to be used for access control during the 2020 Olympic Games in Tokyo. In health care it could include the monitoring of the use of medication, support for pain management products, and the detection of genetic diseases. An idea put forward by Facebook, in support of Know Your Customer, is that face recognition allows sales staff to pull up a customers social media profile to help them "improve the customer purchase experience".
In the very near future the banking sector is expected to drive fingerprint authentication for ATM's and voice authentication in customer support centres. The basic driver is to eliminate passwords and PIN's, and already China is a leader in the use of biometric authorised payments. Today the Chinese mobile payment market is already worth around $13 trillion annually (led by fingerprint-to-pay apps). And face recognition is being trialed (smile-to-pay) for food purchases.
The healthcare sector is expected to follow banking with the introduction of healthcare biometric technologies.
And there is plenty of talk about in-car biometrics with fingerprint ignition and later biometric passenger monitoring in self-drive cars.
Most of the discussion presented below is to do with the application of face recognition in what are security situations, e.g. access control, boarder crossings, ID verification by the police, mobile payments, etc. But we should not forget the commercial/retail interest in using face recognition to create a "frictionless and magical experience". Part of the 'magic' is to let the technology recede and bring the 'experience' to the front. And the first step is to anonymously recognise attributes of people, such as gender, age, and emotional state. So this is less to do with identifying terrorists, and more to do with helping people find their way through complicated environments such as airports. The systems can be used to track thieves or prevent problem gamblers from entering casinos, but it can also identify when people become irritated as they wait in queues or simply the demographics (gender, age, etc.) of people visiting a shopping centre. Some people have suggested that a clients facial expressions can help salespeople understand preferences, etc., and this could be linked into automated garment recommendations, etc.
How Face Recognition Works
All the work on face recognition boils down to a very simple set of requirements. We need a way to represent faces and to measure the similarity between faces. And that the techniques should have a very high probability of 'matching' pairs of images of the same person (i.e. very low risk of missing a good match or false-negative) and a very low probability of incorrectly 'matching' images of two different people (i.e. very low risk of finding a false-positive).
Biometric systems are divided into two parts, the 'enrolment' module and the identification module. The enrolment module is accountable for training the system to identify a specific person by scanning their physiognomy to create a digital representation. The digital representation becomes a template against which comparisons are made. The identification module captures the characteristics of a person and converts this into the same digital format as the template. The identification stage attempts to compare the newly acquired template to every template in the database and answer the question "Who is X?". An alternative approach is simple verification, which answers the question "Is this X?".
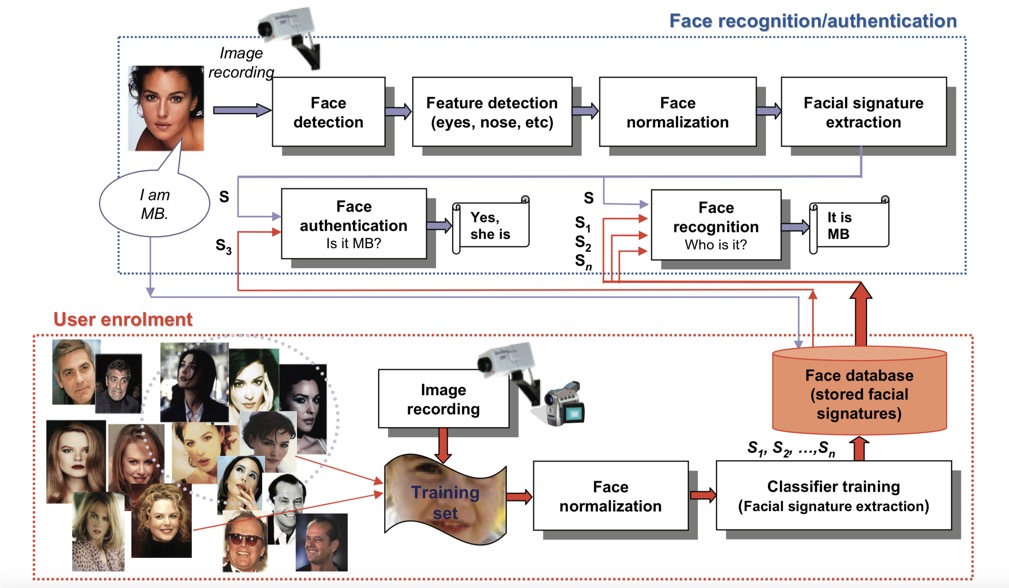
Above we have a very simple outline of the basic elements in a face recognition system. We can see that the first step is to find all the faces in an image taking into consideration that different faces can be in different positions and be of different sizes (and some images might not contain any faces). In addition each face will not be fully face-on, will be differently illuminated, will have a different facial expression, and could be partially occluded by hair, glasses, etc.
Below we have a system that found about 900 faces in a crowd of 1,000 people (the redder the frame, the better the detection).

Once each face has been detected, salient facial features will need to be identified, e.g. eyes, nose, mouth, shape, etc. And in video streams the faces will need to be tracked or followed. Then some form of normalisation according to a set of basic rules will be needed, e.g. find features and 'landmarks' such as edges, shape, texture, colour, etc. The detected faces will need to be in a format that is equivalent to the template used to store the library of known individuals (after user enrolment).
And there are a lot of ways to extract features, all aiming to improve invariance due to pose, illumination, occlusion, etc., and produce a high positive identification rate with a very low risk of failure and very low false negatives.

History of Face Recognition
There is a long history in 19th C Europe of the pseudoscience of physiognomy (see "The Return of the Face") driven by the desire to read character and social status into peoples faces. Also in the UK the Habitual Criminal Act of 1869 defined the need for a way to classify records of habitual criminals (or the 'dangerous classes' as the Victorians would call them). The Prevention of Crimes Act of 1871 required that a registry be kept of every person convicted of a crime, and this registry would gradually be expanded to contain fingerprints, photographs, and a so-called 'methods index' describing a criminals 'calling card'. In fact the first photographs were of habitual drunks. The Habitual Drunkards Act of 1879 allowed the incarceration of drunks in asylums for treatment ('inebriate reformatory'). The police created photographic albums of drunks that were circulated to licensed premises. I suppose we see here the foundations of modern-day face recognition.
Already in 1872 emotions through facial expressions and patterns were studied by Charles Darwin (1809-1882). In 1882 the Bertillon System, named after a French police officer, was introduced as an identification system based upon the physical measurement of the person (see below). It was this system that was eventually replaced by fingerprints.

In 1888 Francis Galton (1822-1911) introduced facial profile-based biometrics (see the Wikipedia entry on psychometrics). Galton also wrote that the fingerprints were the most beautiful and characteristic superficial mark on a human body. This added additional support to the ideas of Henry Faulds (1843-1930). In 1886 Faulds had proposed to Scotland Yard the concept of fingerprint identification based upon the work of William Herschel (1833-1917) who in 1860 had started to use fingerprints in India to identify criminals. At the time Scotland Yard had dismissed the idea, but finally a system based upon the work of Galton (1892) was adopted in 1901.
In the early 1920's Dr. Carleton Simon (1871-1951) founded in the US the International Narcotic Criminal Investigation Bureau and proceeded to compile a database that eventually contained the photographs and fingerprints of over 100,000 people convicted of drug-related crimes in 700 American cities and 27 foreign countries. In 1935 Simon would suggest with Dr. Isadore Goldstein (1905-1981), an ophthalmologist at Mount Sinai Hospital, that the pattern of blood vessels in the backdrop of the eye would be just as effective as a unique identifier as fingerprints. It was only in the 1970's that the first retinal scanning device was patented. Some references suggest that Goldstein also went on to established a system using a standard pattern classification with 21 facial features, including subjective features such as ear protrusion, eyebrow weight, nose length, etc.
Woodrow Wilson Bledsoe (1921-1995) was the first to look at semi-automatic face recognition using a hybrid-human-computer arrangement, where identifying marks were entered on photographs by hand (using a so-called RAND tablet).

Much of Bledsoe's early work on recognising faces was never published because it was funded by the US DoD. The key problems he identified were variations in illumination, head rotation, facial expressions, and ageing, and these are still problems today.
In the 1960's the US started to look at how to program computers to extract features and identify human faces, and in 1973 Martin A. Fischler and Robert A. Elschlager published a paper entitled "The Representation and Matching of Pictorial Structures" about how to find an object in photographs using a generalised set of primitives and parameters. What is interesting is that their image-matching experiments used faces. Albeit with only 15 grey-scale face images they nevertheless produced a useful model that included eyes, nose, mouth and head edges, as seen below. Even then they were dogged by the problems of poor image quality.
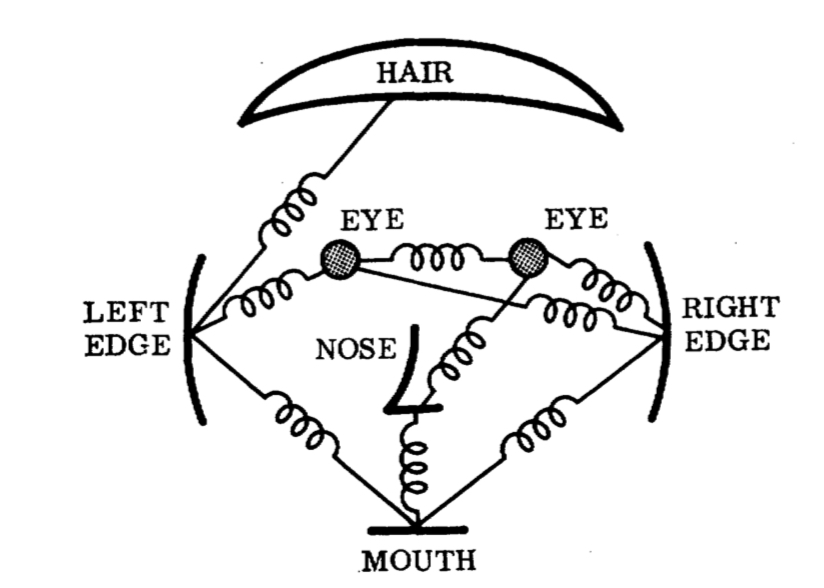
I've not found the reference but it has been reported that Fischler and Elschlager went on to introduce shades of hair, length of ears, lip thickness, etc. as additional defining features.
The real problem in the history of face recognition is that everyone just quotes someone else. For example many authors misspell Fischler's name as Fisher.
So in the 1970's face recognition was limited to identifying feature points on a face, classifying faces into a few different categories, and finding correspondences in small collections of images. In 1970 Michael David Kelly in his thesis entitled "Visual Identification of People by Computer" tested on 10 individuals how a computer might be used for face recognition. In his 1973 thesis "Picture Processing System by Computer Complex and Recognition of Human Faces" Takeo Kanade was probably the first to design and implement a fully automatic face recognition system. He demonstrated that the system worked as well as any human or manual system, i.e. with a correct identification rate of between 45% and 75%. Both used a system of measurement based upon the so-called Procrustes analysis (distance between two facial landmarks).
Almost by tradition, the 'history' of face recognition often goes on to mention the work of Zhujie and Y.L. Yu, from Hong Kong. In 1994 they published "Face Recognition with Eigen Faces" in which they used so-called eigenfaces to represent the human face under different environmental conditions, e.g. face size, lighting, and head orientation. The whole idea was to produce a smaller set of basis images that represented the original training images. However it's worth mentioning that the first use of eigenfaces for face recognition was made in 1987 by Lawrence Sirovich and a M. Kirby. In their paper "Low-Dimensional Procedure for the Characterisation of Human Faces" they used pattern recognition techniques to develop a way to economically represent an image in terms of a best coordinate system that they termed 'eigenpictures'. In 1991 Mathew Turk and Alex Pentland in their paper "Eigenfaces for Recognition" developed the technique so that the system could learn and later recognise new faces in an unattended manner. In 1997 Peter N. Belhumeur, David J. Kriegman and João P. Hespanha in a paper 'Eingenfaces vs. Fisherfaces' proposed another face recognition algorithm 'Fisherfaces' which was insensitive to large variations in lighting direction and facial expression, and was claimed to have a lower error rate than the eigenfaces technique.
Interestingly, the article on eigenfaces on Wikipedia makes no mention of the work of Zhujie and Yu, but they continue to be referenced (cut and pasted) in many scientific articles.
Also many of the 'histories' of the subject don't mention Teuvo Kohonen who published a book in 1989 entitled "Self-Organisation and Associative Memory". He demonstrated that a simple neural network could perform face recognition for aligned and normalised face images. The type of network he used computed a face description in the form that is now known as 'eigenfaces'. The system was not successful because of the need for very precise alignment and normalisation. What Sirovich and Kirby did was introduce an algebraic manipulation that made it easier to calculate eigenfaces, and they showed that you needed less than 100 eigenvectors to accurately code carefully aligned and normalised face images. What Turk and Pentland did was to demonstrate that the residual error when coding the eigenfaces could be used to detect faces in a natural background. It was this step, being able to detect and localise faces in a minimally contained environment, that sparked a new interest in the topic of face recognition.
Until the late 1980's the basic approach to face recognition was to use face metrics, i.e. to characterise features on a normal face picture, such as distance between the eyes, etc. These measurements were then stored as a template for future recognition. An intermediate step was the introduction of deformable templates which weighed certain features over others. The eigenface technology works differently, as it changes the presented face's lighting by using different scales of light and dark in a specific pattern (as so-called 'feature space'). The way the light and dark areas are computed causes the face to look different (see the example below). This approach allows the different features of the face to be calculated in the form of eigenvectors, and generally only around 150 eigenvectors are needed to uniquely define a face, and as little as 40 are needed to reconstruct the face. Using this technique the significant features need no longer be eyes, ears, or noses. The real value of eigenvectors is that it is an n-dimensional problems that can be computed optimally, and computational optimisation becomes important when real-time matches are needed in very large collections of images. Another important feature is that eigenfaces are easier to implement using a neural network architecture.
The eigenfaces approach introduced a valuable new level of abstraction in face recognition, however it's worth noting that skin colour and texture are still important features, and other features such as the mouth and eyes are still used to preform a normalisation prior to the feature extraction process.


Alongside the work on face recognition there was also extensive work on developing an institutional approach to identifying people. It was in the 1880's that photo-identification of a person's face started to be used, however until WW I most people did not need an identity document. It was in 1914 that the US required the inclusion of a photograph in all new passports, and the UK and Australia followed suit in 1915. The shape and size of identity cards was only standardised in 1985, and the smart passport was standardised in 1988.
It was in the 1990's that there was a growing interest in automated, real-time facial identification for checking passports, ID's, driving licenses, and social security rights and privileges.
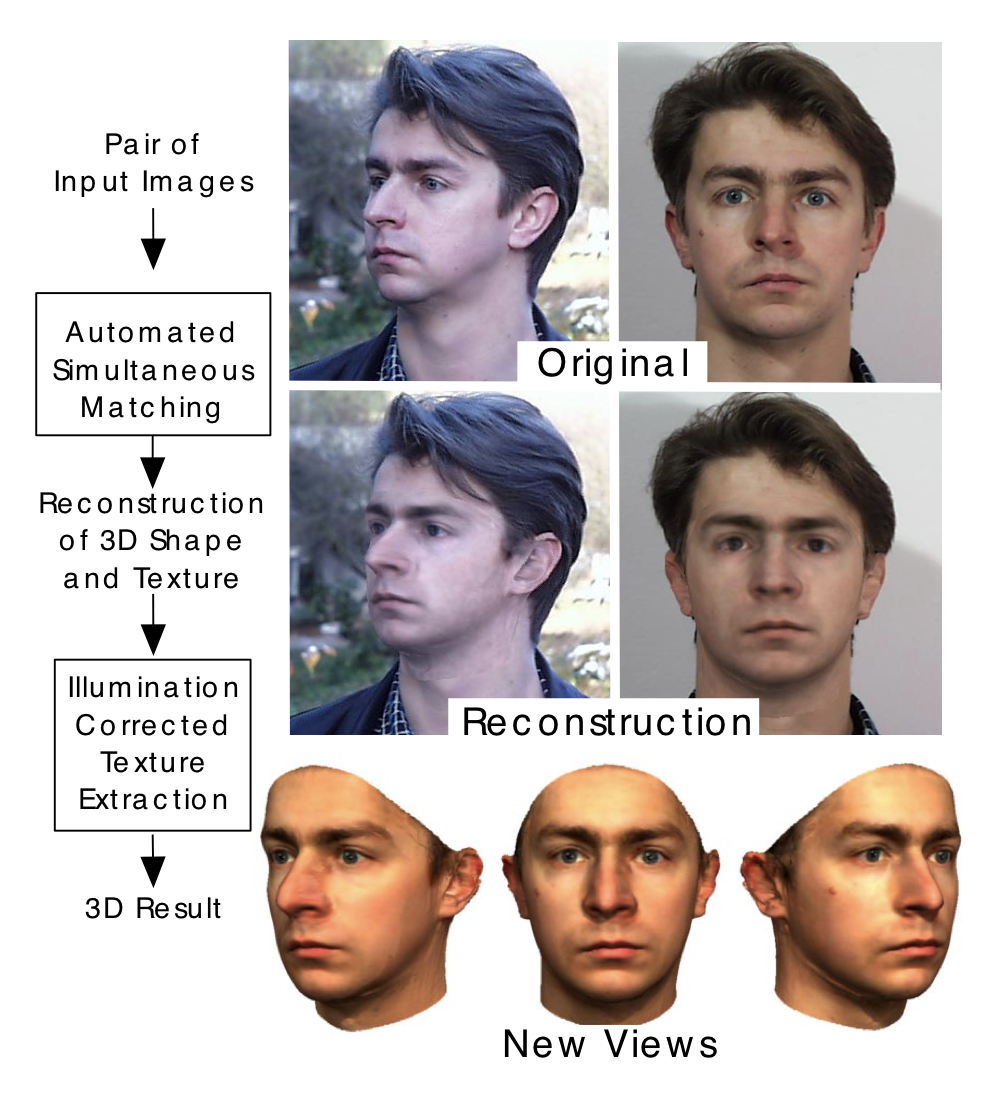
In 1999 Volker Blanz and Thomas Vetter published a paper "A Morphable Model for the Synthesis of 3D Faces". The idea was to take a 2D face image and match it with features (shape and textures) from a 3D database, thus creating a 3D model from the original 2D face image. From this new faces and expressions could be modelled (below we can see the success of the approach). Vetter continues his work at the University of Basel and Blanz is at the University of Siegen.
In 2001 Paul Viola and Michael Jones published the first object detection framework that worked efficiently in real-time, and the work was specifically motivate by the problems of face detection.
Also in 2001, MIT proclaimed biometrics as one of the top ten technologies that would change the world (along with brain-machine interfaces and natural language processing). At the time Joseph Atick predicted that the smartphone would both become our preferred transaction device and our passport or ID. He concluded that the smartphone would need strong security through biometrics. Of course the prediction was that within two to three years (i.e. by 2003-2004) passwords and PIN's would be disappear!
Throughout the 1980's, and still on-going, people studied how face recognition works in our brains. Today the idea is that face recognition is a dedicated process in our brains, and that certain cells are exclusively tuned to recognise human faces or face components. So the suggestion is that face recognition is both a special process in our brains, and that there is a special place in the brain dedicated to face recognition. In addition studies suggest that the identity and expression processes separate early in the facial perception procedure in the brain, i.e. that facial expression is treated differently from facial recognition. It is not clear if the brain exploits colour in processing facial information, however it is certain that colour becomes increasingly valuable as viewing conditions degrade. A very limited series of studies have looked at the number of variables or dimensions that a person uses for human recognition. Initially it was proposed that about 100 dimensions were needed, but this has now dropped to about 70 dimensions because it has been found that facial symmetry plays an important role in face recognition in the brain. Whilst many alternative techniques are now used for face recognition, the measure of important features or landmarks on the face still can provide some insight. One relevant issue is that discarding certain facial features or parts of a face can actually lead to a better system performance. Work is still needed to understand what information is actually valuable and what additional information is just added noise.
Check out this video from Oct. 2018 entitled "The Average Person can Recognise 5000 Faces".
In 2006 Timo Ahonen, Abdenour Hadid, and Matti Pietikainen published "Face Description with Local Binary Patterns", where local binary patterns are visual descriptors used here for facial texture. The idea is to extract the local binary patterns for small regions of the face, then to concatenate them into a single, spatially enhanced feature histogram representing the entire face image. In 2009 John Wright, et. al. published "Sparse Representation for Computer Vision and Pattern Recognition" where the idea was to use sparse signal representation to acquire, represent, and compress high-dimensional signals (i.e. for automatic face recognition). The key problem is to find a way to represent a face (signal) as a sparse linear combination of the training signals stored as a kind of dictionary or codebook. I will admit that this last paper is beyond my limited command of the topic, but fortunately Wright published a tutorial in 2011 which might help the reader (it did not help me). What was shown was that the approach was good in dealing with occlusion and disguise. As far as I can see work continues in order to try to find better ways to integrate and exploit datasets consisting of images extracted from various camera orientations (i.e. using the mutual dependence amount samples).
Through the 1990's and 2000's the eingenfaces model, a generalised holistic approach to obtain a low-dimensional representation, was the focus, but the problem was with uncontrolled facial changes that deviated from the prior assumptions. In the early 2000's researchers turned to local-feature-based face recognition, but the problem was that each system was hand-crafted. There were limitations to the systems ability to distinguish between similar faces, and also the systems were complex and often bloated. In the early 2010's local filters were introduced to help systems learn to distinguish between similar faces, and an encoding codebook helped make the programs more compact. But now the problem was when facial variations were not simple smooth variations between one another. There was progress, but it was incremental and slow. The real problem was that unconstrained facial changes due to lighting, pose, expression, or even disguise, were treated separately. Systems seemed to have reached a ceiling of about 95% accuracy for real-life applications. These systems were classed as 'shallow', and as we will see below everything changed in 2012 when AlexNet won the ImageNet competition by a large margin.
Generally speaking, today the use of 'deep learning' can speed up face-scanning, as the idea is to learn from the data that is being processed. Systems generate a 'unique face print' for each person by reading and measuring 100's or even 1,000's of 'nodal points', including the distance between eyes, the width of the nose, the depth of eye sockets. etc. Increasingly surveillance systems recognise height, age, and colour of clothing. etc. For example, the iPhone 'Face ID' uses the TrueDepth camera to create a depth map or 3D model of the face from 30,000 infrared dots (see below).

Many face recognition system claim to be able to deal with hats, scarfs, glasses or contact lenses, and even if part of the face is covered by a mask. The reality is that the performance of face recognition systems can vary a lot. If the reader is interested they can check out some of the industry leaders such as Amazon Rekognition (see below), Kairos, Trueface.ai, Face++, IBM Watson's Visual Recognition, and Microsoft Face API.

For a reasonably up-to-date view (2010) of how face recognition algorithms work check out the very accessible thesis of Ion Marqués.
For a state-of-the-art review check out "Deep Face Recognition: A Survey" (2019) by Mei Wang and Weihong Deng from China. They introduce their work with a mention of the four milestones of face recognition:-
A holistic approach in the 1990's tried to limit the number of variables (dimensions) used by making some distributional assumptions. But the problem was with uncontrollable facial changes that occur, such as ageing, expressions, etc. The meaning of holistic in this sense is that the methods tried to use the entire face region as an input (as opposed to local feature extraction).
In the early 2000's handcrafted local descriptors became popular, and local feature learning was introduced in the late 2000's. Systems became more robust but facial appearance variations were still problematic. Progress was slow, and involved separate improvements to problems such as lighting, pose, expression, disguise, etc. So the systems were often considered unstable, or producing too many false alarms when applied in the 'wild', i.e. real-world applications.
In 2012 AlexNet won the ImageNet Large Scale Visual Recognition Challenge with a result that was 10.8 percentage points better than the runner up. The approach taken was computationally expensive, and used an approach called deep learning, of which convolutional neural networks is one example. The approach showed strong invariance to face pose, lighting, and expression changes. In 2014 DeepFace performed nearly as well as a human working in unconstrained conditions (97.35% vs. 97.53%). So research shifted to deep-learning approaches, and today many systems claim 99.80% accuracy.
The paper of Mei Wang and Weihong Deng is worth reading for those looking to get a fuller understanding of the technology behind face recognition, but it's not an easy read. Ali Elmahmudi and Hassan Ugail recently published (Oct. 2019) a paper entitled "Deep Face Recognition Using Imperfect Facial Data", which also tries to summarise the state-of-practice.
Daniel Sáez Trigueros, Li Meng and Margaret Hartnett in a 2018 article entitled "Face Recognition: From Traditional to Deep Learning Methods" managed to summarise the situation today. They noted that initially researcher focussed on hand-crafted featured such as edges and texture descriptors, and then looked to combine that with machine learning techniques (principal component analysis, linear discriminant analysis and support-vector machines). The difficulty was to develop systems that were robust to the variations encountered in real-life (unconstrained environments). Researchers focussed on specialised methods for each type of variation, e.g. age-invariance, pose-invariance, illumination-invariance, etc.
Today this approach has been superseded by deep learning methods based upon convolutional neural networks (CNN). The main advantage of this approach is that the systems can be trained with very large datasets, and they can isolate the best features to represent that data. The availability of faces 'in-the-wild' on the web means that large-scale datasets of faces can be compiled containing real-world variations. CNN-based face recognition methods can be trained to learn features that are robust to real-world variation.
The authors highlight the significant accuracy improvements made with CNN, but they also noted that labelling face images is expensive and CNN is slow to train and deploy.
NIST Face Recognition Evaluation
To understand the performance of face recognition we must start somewhere. And that somewhere is with the NIST Face Recognition Prize Challenge 2017.
Within this face recognition challenge we can see the technologies being tested for the two key functionalities, i.e. verifying if two images are of the same face or not, and identifying a face cropped from a video frame when searching a large gallery of portrait photographs.
But what do these tests really mean?
Verification is typically where a person cooperates by providing an image of themselves, and this image is then compared with a known image of the same person. This type of comparison is typical in authentication and access control applications.
Actually the tests reported here were for non-cooperative and unconstrained photojournalism imagery. This means that a database of 141,331 face images of 3,548 adults were cropped from the images found on the Internet.

On the positive side the images were mostly taken by professional photographers and thus were usually well exposed and well focussed. However, being taken from the Internet means that the images might have been resampled and will have undergone various compression routines. As you can see from the above it also meant that the face might not be full-on (i.e. yaw and pitch pose variations). Some of the images might have been almost profile images, and some faces might have be occluded by hair or hands.
Tests were done between two images known to be of the same person, and between images known to be of different people (i.e. impostor comparisons). Given the number of face images and the number of known individuals, this meant nearly 8 million genuine comparisons and nearly 40 million impostor comparisons.
The challenge was to have the lowest 'false non-match rate' at a 'false positive match rate' of 0.001 (i.e. 1 in a 1,000). What this means in practice is that it's very important not to have a high risk of a false positive match, and then the aim is to obtain the lowest false non-match rate (not finding a match when it should have been found).
The best result was from the Russian company NTechLab (they won $20,000). Their result of a 0.22 false non-match rate at a false positive match rate of 0.001 would be totally unacceptable for an access control application, but it is for non-cooperating people and images that are far inferior to those normally found in an access control situation. The key advantage of the winning algorithm was that it could recognise individuals whose head orientations varied widely.
Identification was where a face was cropped from a video frame and a search was made in a database of cooperative portrait photographs. So the test here was to capture a face and find it in a database of 691,282 faces, producing the lowest false negative identification rate at a false positive identification rate of 0.001.

The starting point was the so-called 'enrolment' image, very much like a passport ID photograph. And then the next step was to crop one or more faces from the below sequence, and make a try at a positive identification, with a low probability of getting it wrong.

Tests were performed for both 'mated' images, i.e. images of people known to be in the database, and 'non-mated' images, i.e. faces of people known not to be in the database (so a check of false positives). There are different ways to look at this type of test. The first way (used in this test) is to look at the number of 'mated' searches that failed to provide a match, but always with a false positive identification rate of below 0.001. The winner was Yitu Technology with a score of 0.204 (the prize was $25,000). If the false positive identification rate is relaxed then other algorithms proved better, i.e. the number of positive 'mated' identifications went up but so did the risk of false positives. Yitu Technology has offices in China, Singapore and England.
One additional feature hidden away in such comparisons is the search speed, which could span up to three orders of magnitude. Slow algorithms must offer very tangible accuracy advantages, and algorithms must scale to very large operational databases. An additional prize of $5,000 was given to the fastest algorithm in the identification challenge, provided they met the false match rate of 0.001. NTechLab won this additional test.
NIST Ongoing Face Recognition Tests
In addition to the tests mentioned above, NIST also sponsors an ongoing Face Recognition Vendor Test. The results provide an additional insight into both face recognition challenges and the most recent results. What NIST developed was the photojournalism image dataset, but these ongoing tests look at other forms of images, i.e. a small set of child-exploration images actually used in crime investigations, two different sets of visa images, mugshot images, webcam images, and 'wild' images (it was noted that the possession of child-exploitation images is usually illegal). So the data sets include cooperative subjects (visa, mugshots) and non-cooperative subjects (child-exploitation, webcam, photojournalism)
The way the tests are preformed does not include a training phase. Training is the problem of the algorithm developer, and NIST wanted to mimic operational reality so algorithms are received and used 'as is' without any on-site training or adaptation.
Vendor can mean any industry, research institution or university department, and submissions need not be commercially available, but they must be stable implementations. It was noted that the majority of face recognition companies participate in these ongoing tests, but only a small number of academic teams submitted algorithms.
The reports are quite complex to unfold, but the first report looks at verification (or so-called 1:1 or one-on-one) as of Oct. 2019.
One set of tests is for visa photographs, i.e. full frontal images with usually excellent pose corresponding to US visa issuance patterns (people from more than 100 countries and all ages). The quality of the image is good in that the average interocular distance was between 60-70 pixels. The results logged for 'yitu-003', no. 148, were noticeably better than those of the first 147 tests (I presume that these results are for an algorithm from Yitu Industries). The latest results for these visa photographs was a false non-match rate of about 3 in 1,000 at a false positive identification rate of 1 in 1 million.
A different vendor logged for mugshots a false non-match rate of about 4 in 1,000 at a false positive identification rate of 1 in 100,000. Mugshots in this context were full frontal and with an average interocular distance of 113 pixels. The mugshots were all US adults.
As far as I can tell the above tests were on a relatively small set of images (around 1 million) and for visas there was usually just one photograph per person.
A second report on ongoing tests of identification (so-called 1:N or 'one-to-many') also dates from Oct. 2019, and concerns four datasets:-

26.6 million reasonably well constrained frontal live portraits (mugshots) of 12.3 million people,

200,000 semi-constrained profile views,

3.2 million unconstrained webcam images,
and 2.5 million 'wild' images being a mix of photojournalism and amateur photographs.
What happens is that a vendor provides a 'black box' that receives a search photograph and a database of images and some biographic data. The 'black box' is expected to contain algorithms that detect and localise the face, extract features, and run the identification comparison yielding a ranked list of candidates. It can provide a 'positive identification' with just one candidate (useful in access control situations), or it can provide a 'negative identification' (useful in 'watchlist' detection), or it can provide a ranked list of candidates (useful in crime scene analysis or scanning detainees without ID). Almost all the applications require some form of human review, very occasionally in the case of positive identification applications, sometimes frequently in investigative applications where a live-subject is present.
It should be noted that the different algorithms are trained on datasets created by the developers, and these are not disclosed. Developers will often use machine learning techniques that require iterative training and testing. For the NIST tests the models, data files and libraries are not analysed. This corresponds to a typical operational reality where software once installed is used until it's upgraded. The idea of on-site training using customer data is not considered likely in the near future because to-date training is not a turnkey process.
This second report is far more extensive in the scope of the tests and in the analysis.
As of 2018 the 'miss rate' when searching 12 million people in a gallery of mugshots was less than 0.1%. This was for galleries with multiple images of people, but the result is only slightly higher for galleries where only the most recent image is present. What happens in these cases is that several 'matches' are identified, but almost always the correct match is ranked first (these tests are with a false negative rate of less than 0.04%). Misses are due to ageing (long periods between two images), injuries (bruises to bandaged faces), the presence of a second face possible printed on a T-shirt, of a profile image, or a clerical error (these last three cases should not actually occur in a mugshot database). The error rate for this type of search is two orders of magnitude lower than found in 2010. This is due to the introduction of deep convolutional neural networks introduced in the period 2010-2013. Despite this massive improvement there are still problems with frontal face recognition. What is reported above is the best of the best, and most algorithms don't have low error rates (many have error rates of more than 10%). One difference is that the best algorithms work better with poor quality images and with samples collected long after the initial 'enrolment' image (ageing). Another difference is that some developers trade accuracy for speed. The lowest error rates are obtained for excellent cooperative live-capture mugshots.
Error rates are higher for images collected in non-dedicated photographic environments and where there were no human quality control checks (see above). The poorer level of performance has also been noted with poor quality webcam images and unconstrained 'wild' image datasets. There are situations where a ranked list of possible 'matches' is provided (all ranked images being below some pre-defined threshold). In almost all cases the correct match was ranked on top, but this nevertheless requires human intervention. You can reduced the false positive identification rate (i.e. the list of ranked potential 'matches') by increasing the false negative miss rate. The tradeoff between these two error rates is not easy to determine in many practical situations. As noted above in real-life situations operational databases are contaminated with anomalies that should have been removed, but still produce operational errors, e.g. clerical errors, profiles, faces on clothing, etc.
A separate test was done with 640,000 enrolled mugshots in which images of twins were added. Twins will very often produce a false alarm in an online identification system, although many algorithms do manage to handle different sex twins. The database used is skewed towards identical twins which is not representative of the true population. The problem is that there are quite a variety of 'twinning' possibilities.

Many of the algorithms will pair a same sex twin as first ranked, i.e. a false positive. The algorithms work correctly for different sex twins. But the problem of false positives remains for siblings and for parent-child (people with similar facial features).

And a problem persists with look-alikes of the same national origin.

A test was performed with 3.1 million of the oldest images searched with 10.3 million new photographs (over an 18 year time span). Errors occur when subjects have aged since the enrolling of the reference image (see example above for the same person aged over 18 years). All people age, some more rapidly than others (the use of drugs prematurely ages the appearance of people). Ageing is mitigated by scheduling re-capture, as in passport re-issuance. Results will also be different if the search is against only the most recent photograph, or against an unconsolidated set of past photographs, or against lifetime-consolidated sets of photographs for individuals with multiple presences in the database.
Below we have pairs of photographs of the same person taken two years apart, then taken 12 years apart, and in below that photographs simply taken under different physical conditions. As you might guess there algorithms work well for the first pair, reasonably well for the second pair, and not so well for the third.




Extracted from the same police mugshot database we have the above photographs of the same person spanning a 10 year period. If the first photograph is taken as the 'seed' or template in the enrolled database, the matched scores decrease as the time lapse increases. Performance can differ substantially from one system to another. One of the systems matched the second photograph at 99% but then the performance dropped fast to only 26% after 10 years. Another system found only a 84% match for the second photograph, but was more robust and scored a 58% match after 10 years. What we see above is biological ageing, and as such it's very difficult to predict. However, there is another type of ageing, i.e. the ageing of the template. Faced with the last photograph, the comparison is made against a 'seed' or template that was calculated 10 years ago. Logically the system should age the template photograph before looking for a match. There are systems that have learned to deduce an ageing model using both texture and geometry considerations. Accounting for ageing in the template improves the matching accuracy. More generally some form of template ageing is now also considered useful for both fingerprint and iris matching.
Poor image quality (e.g. lighting, camera, etc.) or poor head orientation, facial expression, or occlusion, will produce poorer results.






The principle reason why results have significantly improvised since 2013 is that deep convolutional neural networks are far more tolerant of image quality problems. However there are still major differences between results found for 'wild' images (the worst), webcam images, and mugshots (the best). With unconstrained images the results are poor unless the threshold is increased to limit false positives, but this also means accepting a much higher error rate.
Dealing with large populations appears not to be a major problem for the best algorithms. The best one had a 0.26% search failure rate for a database of 640,000 images, and a failure rate of 0.31% for a database of 12 million images.
The section on one-to-many identification has many applications, i.e. detection of fraudulent applications for passports and driving licenses, access-control, surveillance, social media tagging, lookalike discovery, criminal investigations, forensic clustering, and simply the detection of duplicates. These types of identification applications are what are called 'open-sets' in that they may contain enrolled 'mates', but not always. Verification applications can include some assumptions about the application environment, whereas identification applications must not make prior assumptions, and yet deliver the correct 'mate' in the first rank position. When no 'mate' searches are made in identification applications they should produce no candidates with high scores.
One of the problems with identification algorithms is how to configure the different types of errors for each application. On the one hand you have the 'false positive' error where a person is incorrectly associated with one or more enrolled images. On the other hand you have the error where a person is not correctly identified despite the fact that they are enrolled in the database (practitioners prefer to look at 'hit rates'). In some applications the threshold might be set very high so that false positives are very rare and that any 'positive' implies an action (e.g. watchlists). In other applications the threshold could be set low, producing long list of candidates that require human adjudication (e.g. criminal investigations). In the case of something like visa, passport or driving license fraud, the threshold might simply be set as a function of the manpower available (i.e. the service has the manpower for 10 reviews per hour so sets the parameters to obtain 10 mis-matches per hour).
False negatives represented 0.39% of the total number of tests performed. These errors were usually due to poor image quality, profile views, tattoos contain facial images, and ageing between the image pairs.
False positives represented 0.56% of the total number of searches. These errors were usually due to profile views, faces in the background, t-shirts containing faces, tattoos contain facial images, and clerical errors.
The report concluded that order of magnitude accuracy gains have been made since 2014 for the best algorithms, and that the industry as a whole has made broad gains. In addition lead developers are achieving results for webcam images that are similar to searches on mugshots.
Areas for further analysis include the causes for recognition failure, the performance of human-in-the-loop systems such as at boarder control gates, a comparison with human recognition accuracy in forensic applications, and the recognition of people in video sequences.
An interesting side topic is the draft report on automated face morph detection. Morphing is the blending of two or more faces to form a single photograph that looks realistically like all the contributing subjects. It is a very easy process and costs almost nothing. There is a risk that these morphed images are used to obtain identity credentials that will fool both human controls and face recognition systems. The test report only involves five algorithms from three academic institutions. The likely application is going to be about identifying morphed images in a huge flux of legitimate photographs. At the moment, for a reasonable false detection rate of 0.01, the morph miss rates (non-detection rate) was very high (0.88). One algorithm registered a morph miss rate of 0.05 but it was optimised to detect the use of one particular morphing process.
If the morph is a mix of two people, then the detection algorithm works better when the mix is near 50%-50%, but it works badly when the mix is nearer 90%-10%. In addition, the detection algorithms work better on digital images, but far less well on images after printing and scanning (virtually no trace left of image manipulation).
Below we can see two photographs of two different people, followed by the product of morphing using an Internet tool, and the fourth image is the same one printed and then scanned.


A realistic application would be that a suspected morph is compared to a live capture taken at a control gate. The algorithm must decide if the image is a morph, and with what degree of confidence. In principle the second photograph is additional information, however the morph miss rate for most algorithms is still 100% at a false detection rate of 0.01, and still well above 80% at a false detection rate of 0.1. Some algorithms perform better at detecting morphed images without the use of a second photograph.
NIST Face Recognition in Video Streams

For example, above we have five shots taken from video captured at the time of the Boston marathon bombing in April 2013. The top two photographs are Tamarlan Tsarnaev and the other three photographs are his younger brother Dzhokhar Tsarnaev. Three images of each of these two people were added to a police database with 1 million mugshots (photographs taken from social media). A search was made using the images clipped from the video footage.

When these tests were performed in 2013 we can see for the younger brother two of the photographs were ranked at 1,869 and 12,622, but his high school graduation photograph was ranked 1st.

For the older brother the results were far less impressive. As of 2013 this highlighted the potential, but also the problems of illumination, ageing, quality of image and occlusion (hat and sunglasses).
So there is an increasing interest in automated 'face in video', i.e. face recognition of non-cooperative subjects in video streams (and in most cases they do not know they are being filmed). Turning to the NIST trials, the idea was to collect faces extracted from video sequences and search them in a database of 48,000 portrait-style enrolled identities. The reported dates from March 2017, but the data and results were submitted in December 2015.
Face recognition is harder for video streams than for portrait-style photographs. As we have seen faces can appear with a range of resolutions, orientations, and under different illumination conditions. Subjects are moving, so faces must be tracked over time, but faces can be blurred at times, or even occlude by objects or other people. In addition the video streams are dependent upon the quality of cameras, the illumination, and on the data compression used. Finally the 'target' face can be mixed up with other faces that might look similar.
In parts of a video sequence there might be no faces, and faces could be set against a cluttered and active background. Then in some segments people are moving, not necessarily along the optical axis of the camera. As people move the lighting can change and occlusion can occur.
There are different situations, e.g. searching video against enrolled still images, searching still images within a video sequence, and searching video to video. And a lot will depend upon the question, i.e. verify that people in the video sequence are in the enrolled database, or verify that they are not in the enrolled database. In many applications it's the 'blacklist' search that is wanted, i.e. check that the people are not in a 'wanted' list. In this case the probability that the subjects are in the database is very low, and it's important to reduce the risk to miss a 'person of interest'. Less frequent, but still of interest, are the 'whitelist' applications designed to allow a rapid flow of people through an access portal, etc. yet keep 'false alarms' low.
There is also a third application where no identification is made, and where the goal is to link an image across two events, e.g. the person entered and then left.
Most of the practical applications will involve the need to identify (not simply verify) the subjects in the video stream in a so-called 'open universe' situation, i.e. where some subjects will not have a corresponding 'mate' in the enrolled identifies (i.e. people who are not in the database). So the algorithms must minimise both false positive errors (i.e. an unenrolled person is recognised as being in the list) and false negative errors (i.e. an enrolled person is missed). This balance is crucial with 'watchlist' applications, where the vast majority of individuals are not in the database (i.e. the system must be configured to produce few false positives so that trained reviewers are not swamped with false alarms). This requirement sounds reasonable, but in fact the academic community is more used to working with computer vision and pattern recognition benchmarks designed to classify an object as one of a closed group of exemplar objects. This is equivalent to assuming that everyone photographs must be in the database, and the problem is to find and rank the 'best' matches. Some teams do include impostor comparisons in a one-on-one verification, but here we are looking at one-to-many identification, where 'many' can be very large, and where false alarms can easily occur. Too many systems assume the prior probability that a 'mate' in the database exists (i.e. a probability close to 1), whereas in many real-life situations the prior probability will be many orders of magnitude below 1 (e.g. drug interdictions at a boarder crossing is estimated to be 1:10,000 and in a counter-terrorist application it will be lower still). Also the academic community is increasingly looking at ways to overcome problems with pose, illumination, etc. whereas for government applications the camera and illumination can usually be controlled even with non-cooperating individuals. The key in these situations is to have a very low false positive rate, and an ability to adjust the recognition threshold as a function of the manpower available for human adjudication.

Everything starts with face detection, in an environment of differing resolutions and head orientations. Algorithms vary by an order of magnitude in the number of faces they detect. Non-faces are detected, and actually faces are missed. In a practical situation such as a transport terminal the number of faces detected can vary between 8 to 150 per minute, when the most accurate algorithms are tracking 10 to 15 faces a minute. Tracking too many faces need not necessarily affect the accuracy of a system, but it does yield more false positives because poorly tracked faces will yield higher impostor scores. Algorithms that produce the fewest detected faces have an increased false negative identification rate.
As of 2015 algorithms vary massively in accuracy, with errors ranging from below 1% to above 40%. Even the best algorithms, along with professional-grade ceiling-mounted cameras, still have a miss rate of between 20% and 90%.
The data sets used for the tests varied from high quality data typical of a modern custom-built installation, through to legacy CCTV systems poorly suited to face recognition.
Under the best conditions and with the best algorithms, about 17,000 faces were detected in 20 hours of transport terminus surveillance video. Most of the faces were un-enrolled passers-by. The video also contained 480 frontal photographs taken from an enrolled gallery. The best algorithms missed 20% of them, and it gets worse the larger the database of enrolled photographs. Practical applications might be quite different. If investigators have isolated a few faces of interest and wish to scan the entire 20 hours of surveillance video then the miss rate threshold can be set to zero, and trained reviewers can adjudicate the candidate list extracted from the video.

If people are forced to present themselves in front of a camera (e.g. by presenting a barcode token at a boarding gate) then the best algorithms will miss only 6% of people enrolled in a database of 480 individuals. One idea is to photograph passengers at checkin and use those photographs as an access control at boarding. So-called 'whitelist' controls could also be extended to visa checks, i.e. matching people leaving a country against photograph taken during entry controls. Tests have been performed with an 'attractor' to induce a frontal view plus a bottleneck creating a forced delay, however a false positive of 6% is still too high compared to typical access control systems.
However an alternative is to identify people by fusing information from multiple cameras and multiple locations. Firstly identification error rates can be lowered when people go through a volume that is filmed simultaneously by three cameras. Another alternative is where subjects are filmed several times by the same camera and the data fused over time. A third option is to fuse all appearances over several separately located cameras. This fusion over space and time produced a considerable improvement, however this type of application is only useful when location and time are unimportant.
Trials have been done with a video-to-still mode for professional photojournalism and television. Despite the good illumination, focus and composition, the results are poorer than in a ceiling-mounted surveillance setting. The key different is that there is a very wide variation in pose in photojournalism data, whereas for the surveillance data it involves frontal images being searched against a database of frontal photographs. The suggestion is that cross-pose recognition of the human head remained the biggest challenge to better accuracy.
This work just scratches the surface of one-to-one verification of identity. The report lists a number of areas that might one day be the subject of a detailed analysis:
- identification from body worn cameras, license plate cameras, drones and other aerial vehicles
- video analytics, scene understanding, anomaly detection, and spatial boundary violation
- suspicious behaviour and intent detection
- estimation of emotional state
- full body recognition (static and kinematic) including gait recognition
- and the use of imagery from exotic sensors for infrared and thermal emission.
Biometric Technology Rallies
The US Homeland Security ran a 'Biometric Technology Rally' in March 2018 and again in May 2019, and a whole website is dedicated to the results.
The 2018 rally was looking at face/iris systems operating in an unmanned mode in a high throughput security situation. They were interested in 'biometric transactions' taking less than 10 seconds, the performance (correct identity and low failure to acquire), and how satisfied the people (users, targets, etc.) were. None of the eleven participants met the goal of 99% correct identification within 20 seconds, however the best was 97.8% within 20 seconds (and three others were at 95%). Two participants did met the goal of less than 1% failures to acquire within 20 seconds, and four participants were under the 5% within a 5 second acquisition time. Only two participants met the goal of 95% user satisfaction.
The 2019 rally looked at face/iris/fingerprint systems, but it evaluated separately acquisition and matching. Again the goal was to complete the biometric transaction is less than 10 seconds. Eleven of the fourteen participants focussed on face matching. This time seven systems managed to complete the transaction in under 5 seconds. Four of the system met the goal of a failure to acquire rate of under 1% within 20 seconds, but only one participant managed to met the requirement for a successful verification rate of 99% in under 20 seconds. Collectively the overall evaluation concluded that four face matching systems met the overall goal of a high true identification rate and a low failure to acquire rate.
This type of test looks at how system would be used in boarder security, airport security, and physical access control to buildings, and freeing up expensive security personnel. In part it's to do with understanding what to expect from these systems (capture rate errors, collection times, matching errors, user satisfaction), and part is to provide feedback to developers. The overall conclusion was that throughput and user satisfaction was good, but the systems themselves performed from below expectations through to near perfect for face recognition acquisition, but none performed satisfactory for iris or fingerprint verification.
It must be said that some of the participants did not expect to be successful. Some used it to test mockup combinations of technology, others use the rally to test a 'startup' idea and determine if it's worth pursuing. Yet others saw it as a way to show how their technology might work in real-life situations. The best system did require users to 'engage' with the system, but it needed only 2.7 seconds to process each face, had a 0% failure to acquire rate, and a 99.5% true identification rate.
Other Face Recognition Datasets and Trials
Wikipedia has a 'list of datasets for machine-learning research', which includes a list of datasets used from face recognition (I'm not sure it's up-to-date).
What we have seen with the NIST trials is a 'customer' trying to test and understand how well face recognition systems might work as a 'black-box' application in semi-practical access control situations. Other types of tests are designed to evaluate the algorithms used, either as research topics or as commercial implementations. Below we will look at three alternative tests that are in the public domain. In the first example we have Microsoft running an open test to see how well algorithms work when well trained, but faced with substantial variations in pose, age, illumination, etc. Then we have the "Labelled Faces in the Wild" that focussed on algorithm performance when faced with ordinary people photographed in everyday situations. And the last example is the 'MegaFace' that asks the question just how good are the algorithms in dealing with large databases in which the vast majority of photographs are of 'detractors', i.e. people who were not in the training and test data.
At ACM's Multimedia conference in 2016 Microsoft Research released MS-Celeb-1M, a large-scale real-world face image dataset, and 'challenged' developers to recognise one million celebrities from their face images. The starting points was a dataset of one million uniquely identified people from Freebase.
The challenge was to identify 1,000 celebrities sampled from the one million, and for each celebrity there were 20 images scraped from the web and manually labelled. The identifies of these 1,000 were not disclosed and each contestant was asked to provide 5 or less 'labels' for each test image, ordered by confidence scores. A training dataset was provided containing 10 million celebrity face images for the top 100,000 celebrities (but there was no obligation to use it). Microsoft also provided several hundred face images with ground truth labels for self-evaluation.
In fact the challenge involved two different tasks. The first task was on a random selection of test images, which was likely to map well to the training data. The best participant managed a result of 0.734 at the 95% confidence level, and 0.525 at the 99% confidence level. However the other participants were significantly worse at the 99% confidence level (range 0.001 through to 0.417).
The second task was to perform the challenge on a 'difficult' data set specifically chosen to include substantial variations in pose, age, resolution, etc. The results were worse than for the first task, as could be expected, however the same participant also obtained the top score of 0.336 at the 99% confidence level. The winning team was from China.
After these tests Microsoft found that the main dataset was contaminated with noisy or wrongly labelled data, and after cleaning what remained was 3.8 million photographs of 85,000 different people.
However in June 2019 Microsoft decided to withdraw this dataset from public use. The photographs had been collected under the Creative Commons, which allows academic reuse. However the people in the database had not been asked for their consent, and it was found that the database was also being used for commercial purposes. At least two other datasets have also been taken down.
This situation was revealed by Megapixels website which looks to highlight "the ethics, origins, and individual privacy implications of face recognition image datasets".
Another data collection is the 'Labelled Faces in the Wild' (LFW) which is a public benchmark for the research community (it explicitly mentions that it is not intended to provide a commercial benchmark). It is a dataset of 13,233 faces collected from the web. There are 5,749 different people in the dataset, of which 1,680 people have two of more distinct photographs in the dataset. The idea is that research teams (and commercial developers) can use the data for training, and then test their algorithms, or they can integrate the data into a larger training dataset. Once a match test is completed the system provided either a simple 'match' or 'no match', or the identity information of the person in each pair of images. Results can thus be either for simple matches (so-called restricted), for identified matches (so-called un-restricted), and with or without outside data (also with and without labels). Looking through the results, the best-of-group registered about 0.94-0.96 accuracy for unsupervised data without outside data. The results for the best-of-group, when including outside data, registered a 0.89-0.94 accuracy. The results are classified as coming from academic/non-commercial and commercial developers. Most of the commercial developers appear to test for unrestricted matches, and including labelled outside data. I think this means that when a match is found the label can be used to find in the referenced database other images of the same person, which can help validate the original match. In any case quite a number of commercial developers registered accuracy results in excess of 0.995.
At least according to some references, the LFW dataset was instrumental in determining that algorithms developers were able to surpass human performance on face recognition, and approach near perfect results.
The finally dataset worth mentioning is the so-called MegaFace, a large-scale public face recognition training dataset that serves as a benchmark for commercial developers. This dataset includes 4,753,320 faces of 672,057 different people from 3,311,471 photographs downloaded from 48,383 Flickr users' photo albums. This dataset is actually extracted from the 100 Million Dataset (often called YFCC100M) which contains 99.2 million photographs and 800,000 videos, along with user-generated metadata.
There are at least two key differences between MegaFace and LFW, firstly the size of the datasets, and secondly MegaFace tests current performance with up to one million 'distractors', i.e. people who are not in the test dataset (I suppose they are designed to detract from the real answer). As with LFW the datasets are of people 'in the wild' with unconstrained pose, expression, lighting, and exposure. In addition the photographs are of ordinary people, not celebrities. And the dataset contains lots of people, and not lots of photographs of a few people.
Compiling such a dataset is non-trivial. Previous datasets were small collections of celebrities and/or in constrained environments. Governments can compile datasets of mugshot, passport photographs, etc. but these are usually not used openly for research purposes. Commercial companies have also built face recognition databases, but they are usually not openly available for research. This dataset was created because through 2015 results showed that algorithm performance could drop by as much as 70% when the datasets started to be populated by a high percentage of 'detractors'.
What developers do is to download the dataset (gallery), train the algorithms, and then run one or more of the test experiments (probes) and upload the results. The two probe tests used are firstly FaceScrub (106,863 faces images of 530 celebrities taken from the Internet) and secondly an 'ageing' dataset originally launched in 2004 and based upon a face and gesture project FGNet launched in 2000. I'm not sure exactly what FGNet contains now, but originally it was composed of 1,002 images of 82 Caucasians in the age range 0-69 years old.
The description of the tests and results is very short and not that easy to understand for a 'outsider', however the first test looks to have involved training on FaceScrub, and then using a probe or test set also from FaceScrub (FaceScrub was created in 2014). The results show that some the best algorithms are working at above 99.8% matching accuracy (at a false acceptance rate of 1 in 1 million). There is a specific age-invariance data set for testing how well the algorithms deal with ageing. In this case the best are working at only about 70%-78%. My guess as to what this means is that the algorithms are trained on FaceScrub, then that dataset is 'hidden' within the MegaFace dataset of 'distractors', and then the FaceScrub dataset is used as a probe or experimental test, and the the accuracy of identifying those 530 people within a dataset of over 1 million images is assessed.
There is a second test option, which (as far as I can understand) involves training only on the MegaFace dataset, and then after 'hiding' the FaceScrub in the MegaFace dataset, the test probe is to correctly identify those faces from FaceScrub within over a 1 million 'distractors', i.e. the algorithm was not trained on the FaceScrub images. In this case the best-of-the-bunch appear to be working at an accuracy of about 75%-77%, and for the age-invariance tests the best has an accuracy of 61%, but most appear to be operating at under 40%. For more information on MegaFace and MG2 check out "Level Playing Field for Million Scale Face Recognition".
One of the by-products of MegaFace was a better understanding of human performance. Humans trying to identify 99 different people in a database of 10,000 'detractors' only ranked 1st the right match 23.9% of the time, although they did put the right match in the first 10 rankings 91.1% of the time. The 99 people were a variety of well known and lesser known celebrities, and in fact human performance was sightly better for well known celebrities (25.1% 1st ranked vs. 22.7% for poorly known people).
So, just how good is face recognition?
We know that facial recognition is being increasingly employed for everything from boarder control to tracking thieves in supermarkets. We know that in several US States facial recognition systems have been banned, in part due to the problem of false positives.
In May 2019 it was revealed that half of all adult Americans have their identities used in police face recognition databases (that's 117 million people).
So just how good is this technology in identifying individuals under different conditions? Certainly some of the Chinese companies active in the field claim nearly 100% accuracy in correctly matching surveillance footage to their databases. They claim to be able to also use gait patterns and distinguishing body features, and to be also able to handle partially exposed faces. In some Chinese cites this technology is used to name and shame minor offenders, to spot criminals in crowds, and to confirm the identity of passengers in airports. Their systems are constantly adding more photographs to the database, and are now including other features such as height, build, age, colour of clothes, etc. Even with a mask the systems are able to track on the exposed part of the face and produce a list of candidates with a high tolerance to false negatives. It has been stated that the systems are now able to reach 100% correct identification even when only the top, right-half or three-quarters of the face is visible. System performance drops considerably if only the eyes and nose are visible, or if only the bottom part of the face is visible. But these results were expected to improve as more training data is included for partially occluded faces. Some companies are now claiming to be able to identify people just by their gait, even with concealed faces or with their back to the camera.
The consensus is that the accuracy rate of facial recognition could become almost perfect if the systems are training with enough data. However, there is a concern that vast digital ID libraries are being created without the consent of individuals. In China it is reported that they are linking face recognition with government record systems and social networks, and they even issue people social scores which can be affected by bad driving, jaywalking, posting fake news, or just buying too many video games. It's even been suggested that good, honest Chinese citizens will get travel discounts, and bad behaviour could mean a person is banned from flights and trains, and could even have their dog taken from them.
So we know that some of the best algorithms achieve near perfect results on the 'Labelled Faces in the Wild' benchmark, and that they surpass human performance. Yet are we confident that face recognition systems used by the police are quasi-perfect? Or if we lose our smartphones, that no one will be able to use the face unlocking program to gain access to our personal data. Are we sure that the surveillance systems installed in our public spaces will detect known terrorists and leave everyone else in peace? Are the systems really that good in finding true positive matches with negligible false positives?
Just to highlight that there is much that the research community still does not understand concerning the way algorithms act in given circumstances. As an example, in 2015 tests with MageFace showed that many algorithms that were expected to perform well with frontal faces, actually performed less well (by about 5%). The 'distractor' database was divided into only frontal images and non-frontal images, and the most commonly used algorithms registers identification rates for full frontal 5% lower than for non-frontal.
One reason was that the test dataset tended to be biased to frontal images, and therefore was less likely to incorrectly match to non-frontal images in the 'distractor' database, i.e. people who were not in the training or test datasets. Another possible explanation was that algorithms might trade performance for a given pose against a need to generalise across different poses, and thus it might perform worse for predominantly frontal recognition. This highlights that even people who implement specific algorithms don't necessarily understand fully how they might perform in real-life.
What are some of the non-technical issues with face recognition?
In the report 'The Perpetual Line-Up' from Georgetown University (May 2019) they list some of the major non-technical issues with face recognition, namely:-
US law enforcement face recognition networks include over 117 million American adults, and by using the driver's license databases most of these adults are law-abiding citizens.
The US FBI FACE (Facial Analysis, Comparison, and Evaluation) unit can search against databases that include 411.9 million photos, including 185 million photos from ID's and driving licenses. Their next-generation system includes 25 million state and federal crime photos.
The benefits are real, but most applications of face recognition are unregulated.
For example only five US states regulate the use of face recognition, whereas many more regulate the use of geo-location tracking, drones and automatic license plate readers.
At least five US cities (including Chicago, Dallas, and Los Angeles) run real-time face recognition on street cameras.
Only two agencies purchased technologies based upon accuracy tests, and it would appear that vendors 'sell' impressive performance statistics but at the same time disclaim liability for failing to meet that performance.
For example, FaceFirst claim 95% identification rate based upon the NIST ongoing vendor trials, yet they state that they make "no warranties as to the accuracy or reliability" on their facial recognition capabilities.
Most police departments rely on police officers to decide on 'matches', but they make the wrong decision about a match half the time.
Face recognition disproportionately affects African Americans. Mugshot databases include a disproportionately number of African Americans. So in principle the systems should be better in identifying them, however they are in fact less accurate for black people.
This article in the New York Times looks at the racist history and pseudoscience associated with the past use of face recognition.
Only now are some US police forces acknowledging that they use face recognition, despite having used the technology for anything up to 5 years.
Most of the face recognition systems in use have never been audited, and in some cases the system have been in use for up to 15 years.
One of the main conclusions in the report is that facial recognition is too powerful a tool to go unregulated.
In May 2019 Georgetown University also produced a very short report 'Garbage In, Garbage Out' which highlighted the problem of flawed data used in face recognition. What they found was that many police departments edited the photograph of a suspect before submitting it for face recognition. Editing features are often an integral part of software packages. Techniques include replacing an open mouth with a closed mouth, replaced closed eyes with open eyes, copying and mirroring part of a face to create one single face, adding a similar nose, mouth or brow to a low-quality or blurred image, and creating a face from two photographs of different people so as to 'match' a poor quality photograph of a suspect. Another technique is to create a 3D model of the head and rotate it to create a full-front mugshot. In some cases the modelling software will fill-in missing parts of the face with 'averaged' data. If this same process were used for fingerprints it would be a scandal. The police claim that these techniques are only used to provide 'investigative leads…'.
Here is a short video from July 2019 entitled "How Police Manipulate Facial Recognition".
Also in May 2019 Georgetown University produced another short report 'America Under Watch' which looked at biometric surveillance. The authors see the introduction of face recognition in cities such as Detroit (Project Green Light), Chicago, New York, Orlando, Washington, etc. as being the first step to the 'all-seeing' surveillance found in some Chinese cities. They see this technology as challenging concepts of free speech and privacy, as well as introducing a bias in the way systems handle minorities such as African Americans.
The Green Light project in Detroit is a system placed in 500 locations and designed to deter crime. However, in signing up for the project people agree that the police "may connect the face recognition system to any interface that performs live video, including cameras, drone footage, and body-worn cameras". The system also allows an unlimited number of police officers to run face recognition searches on their mobile devices against the cities 500,000 mugshot library as well as State driver's license photographs.
Chicago has a real time face recognition system in place since 2016, including cameras monitoring 20,000 locations, and linked to their mugshot and 'watchlist' system. Interestingly Illinois has one of the most compete set of legislation protecting citizens' biometric data. It guards against the collection, use and dissemination of biometric information without express, written consent - but only by commercial entities (the police are exempt).
And just to remind us that this is not just about the US, here is a short article where a man in the UK was fined £90 for hiding his face from police facial recognition cameras. I wonder what they would have done about so-called 'face jewellery' that is specifically designed to block facial recognition technology. There is also talk of cosmetics specifically designed to confuse face recognition software. Another option is to include facial features (e.g. eyes) in clothing to confuse and fool face recognition. Yet another option is to modify photographs before posting them on social media sites. The modification involves imperceptible changes to images that don't affect the human eye but confuse face recognition algorithms.
Can Face Recognition be Hacked or Spoofed?
When the password was first introduced around 1961, the first password breach occurred almost immediately afterwards. So it's valid to ask if face recognition is secure, or can it be hacked or spoofed? One way to look at the problem is not to ask if a system is 100% secure, but if it's sufficiently secure so as not to make a hack worth the effort (i.e. too time consuming, too expensive, too complicated, too risky). However, if face recognition is to replace the password and PIN then we should expect:-
That it does not produce false alarms
That it does not fail to recognise a valid user
That it's easy and fast, and can be used anywhere
That it produces very few false matches, and
That it's spoof resistant.
One of the basic problems is that face recognition works best when we have lots of examples of a person in the database, and when the input quality is high. But does that make it convenient? The holy grail is face biometrics for mobile authentication (for payments). But are they not easy to spoof? People have hundreds, or even thousands, of digital photographs more or less freely accessible on the web. So face recognition security can't be dependent upon secrecy.

Biometrics, and face recognition, is only going to be useful if we can obtain a reliable match of the genuine owner. But the sensing equipment and set-up must be economically acceptable, and the signal-to-noise must be good. And whatever we do, the system must not be easy to fool by a hacker or imposter.
A hacker might be interested in two alternatives. Firstly they might be interested in creating a false match. For example, at the moment of registration the attacker could be looking to steal the identity of someone (i.e. identity theft). In the world of mobile banking and payments this initial registration process is increasingly called 'onboarding', i.e. the organisational process to take on a new client. And banks increasingly want to use face recognition services as a positive feature to attract new clients, claiming that its ultra-safe and ultra easy to use.
But equally the attacker might be interested in creating many false non-matches in the system, thus rendering it useless for identity authentication.
In a mobile banking and payment situation, the system must prevent the impersonation of a targeted fraud victim. During the acquisition of a new client the system must proof the identity by matching it against an ID, it must protect against duplication, and it must run checks against a 'watchlist' or 'blacklist'. Even better if the new customer ID can be checked against a trusted reference image previously registered. Also the non-match threshold can be set making a false-match impossible, but at the cost of increasing false non-matches with all the associated consequences. When no reference image is available, what is needed is that a face image is acquired that conforms to the requirements of automated biometric identification systems and is citable in court (not yet the case). In order to lower the risk of false non-matches the face recognition systems should be 'enriched' with a selection of the customers potentially non-matchable face images extracted from the web (or from the customers smartphone).
One specific type of attack involves morphing or merging two identify photographs, i.e. the target and the attacker. In situations where a person provides their own printed photograph, it's possible to provide a merged photograph that could be verified successfully as being of the target yet could also be used by the attacker (check out this video 'Fake ID', but it's in German). To overcome this possibility systems need also to automatically detect morphs.
On the upside, the resolution of cameras on smartphones has improved enormously. On the downside the trend for selfies means the web is now full of high-quality images of potential fraud targets taken under all sorts of different conditions (illumination, facial expressions, etc.), creating an additional challenge for face recognition programs. On the upside the face recognition programs have also improved immensely, from a best-of-bunch accuracy of 92.3% in 2010 to 99.7% in 2018.
So face recognition on smartphones can be accurate, convenient, and easy to use, but are they also relatively easy to spoof?

Let's face it, anyone can figure out a way to present a face photograph to a smartphone. They can cut out bits so that eyes blink and there is lip movement. Making a silicon mask does not require that much expertise, even if it does mean capturing 3D face information from the target. Even mixing biometric signals is not that complicated. Latent fingerprints can be found, the iris can be picked out from video footage, and voice recordings of specific pass-phrases can be recorded.
Systems can be developed to deal with many of these spoof tactics. The system could challenge the user to blink, smile, or move in some way. Also systems could look at colour, texture, sharpness of image, parallax, or detect artefacts such as cutouts, etc. Face and voice could be implemented quite quickly, providing a much lower error rate, and making it considerable more difficult to spoof, but will the user accept it? Maybe, if it gets rid of passwords and PIN's.
The problem to detect if a real person is in front of a face recognition systems (e.g. on a smartphone) is now called 'liveness detection'. The most obvious feature of liveness is eye blink detection. The average human blinks 15-30 times per minute, and the eyes remain shut for about 250 milliseconds during a blink. Modern smartphone cameras operate at about 50 milliseconds between frames, so they can be used for eye blink detection. An additional technique can involve measuring the exact surface area of the eyes. Another technique is the so-called 'challenge-response'. The system sets a challenge for the person, e.g. smile, close eyes, nod, make an emotional facial expression, head movement, etc. The responses are analysed as are face geometry changes associated with the response, but some people might not like to have to nod and scratch their nose every time they want to use their smartphone.
Another technique is to use a 3D camera that captures precise pixel depth information. Yet another is the so-called 'active flash' which looks at the light reflected on the face.

Many academic papers state that they focus on non-3D options because making a convincing 3D mask is too difficult and expensive. Firstly there are now 3D printing services that will make a 3D mask for a very reasonable price. But the argument goes that you need a 3D model of the persons face, and its not easy to obtain a 3D scan of a persons face without their consent. However there are now also searches such as ThatsMyFace that specialise in 3D face reconstruction from 2D portraits for sculptures, etc.
We can immediately see that using face recognition for mobile banking and payments is technically challenging. Smartphones have their limitations (CPU, sensors, etc.), and the network and servers also have their constraints. Images will be taken in real-world environments, that could be quite noisy. It is not clear how face recognition systems can be training to perform well under these circumstances. Systems must protect the user against a wide variety of potential attacks, and the customer is often very sensitive to systems that are too complicate or difficult to use.
A final point is to understand what are acceptable for false acceptance rates and false rejection rates (e.g. from the banks view point and from the customers view point). A bank might prioritise a zero false acceptance rate, but this might create a high false rejection rate that destroys ease of use.
For some experts, all of the above is irrelevant since the banks have already decided to phase out PIN's, security tokens, etc. in favour of an enhanced smartphone-based ID check. Voice, iris, fingerprint, etc. might be the answer, but if those options are not available and proof-tested within the next 2-3 years then the banks will introduce face recognition, whether the consumer likes it or not.
A Few References
Facial Recognition is the Plutonium of AI, Spring 2019
Face Off: Law Enforcement Use of Face Recognition Technology, May 2019
Independent Report on the London Metropolitan Police Service's Trial of Live Facial Recognition Technology, July 2019